If you are doing IoT, you are generating data. Maybe even lots of data. If you are doing API calls on each device to store them directly, you are doing yourself a disservice. If you are using something different as an event handler, things are better. If you are like me, you’re using Azure IoT Hub to ingest the events.
IoT Hub
IoT Hub is a great way to ingress data from thousands of devices without having to create a scalable API to handle all of them. Since you don’t know if you will be receiving one event per hour or 1000 events per seconds, you need a way to gather all this. However, those are just messages.
You want to be able to store all your events efficiently whether it’s 100 events or a billion.
Azure Functions ⚡
You could always spawn a VM or even create an App Service application and have jobs dequeue all those messages. There’s only one issue. What happens when your devices stop sending events? Maybe you’re running a manufacturing company that only operates 12 hours a day. What happens during those other 12 hours? You are paying for unused compute. What happens to the week where things need to run 15 hours instead of 12? More manual operations.
That’s where serverless becomes a godsend. What if I tell you that you’d only pay for what you use? No usage, no charge. In fact, Azure Functions comes in with 1 million execution for free. Yes, single function execution. You pay pennies per million executions.
Azure Functions is the perfect compute construct for use in IoT development. It allows you to bring in massive compute power only when you need it.
Storing the events
We have our two building blocks in place. IoT Hub to ingest event, Azure Functions to process them. Now the question remains where do I store them?
I have two choices that I prefer.
- Azure Table Storage (can be done natively through endpoints)
- Azure Cosmos DB
Now let’s assume a format of messages that are sent to our IoT Hub. That will serve as a basis for storing our events.
1 | { |
CosmosDB
CosmosDB allows you to store a massive amount of data in a geo-distributed way without flinching under load. Besides its different consistency model and multiple APIs, it is a fantastic way to store IoT events and still be able to query them easily.
So let’s assume we receive the previously defined message through an Azure Function.
Let’s create our Function. We’ll be using the CSX model that doesn’t require Visual Studio to deploy. We can copy/paste directly this code in the portal.
1 | #r "Newtonsoft.Json" |
Inputs
Then, we need to define our inputs. This is done with the Integrate option below our function.
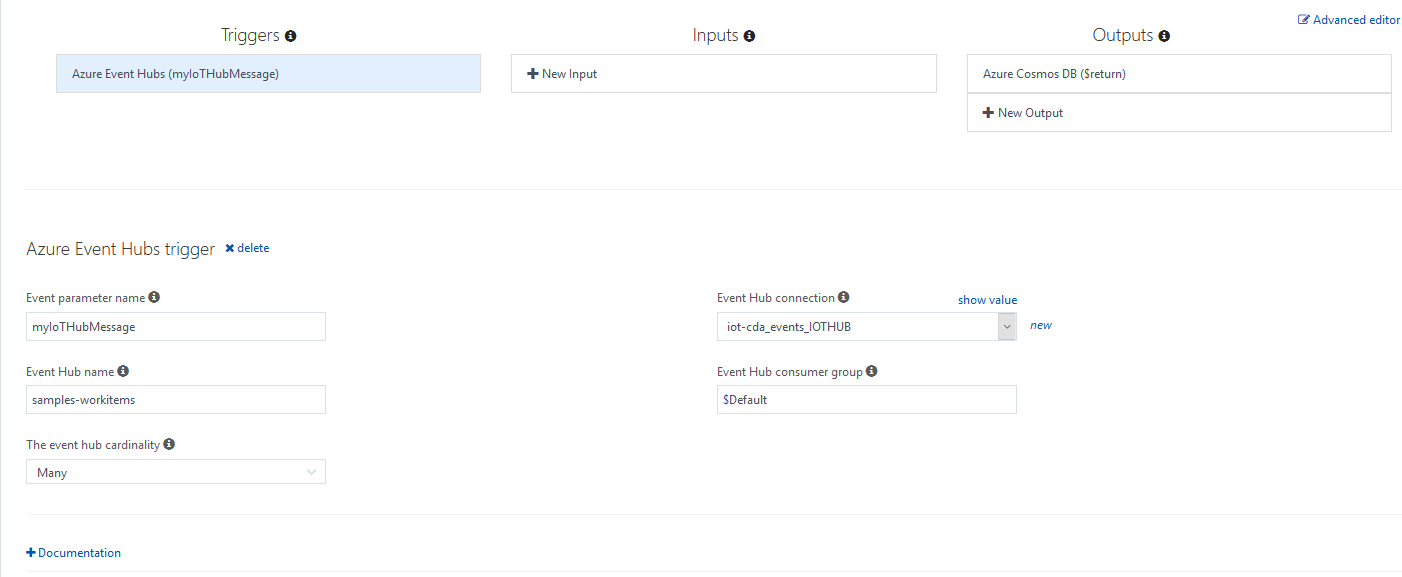
In this section, we define our function parameter that matches with our written function. I also create a new event hub connection.
Output
Now we need to define where things are going to go. In our case, I’m setting a Cosmos DB Output.
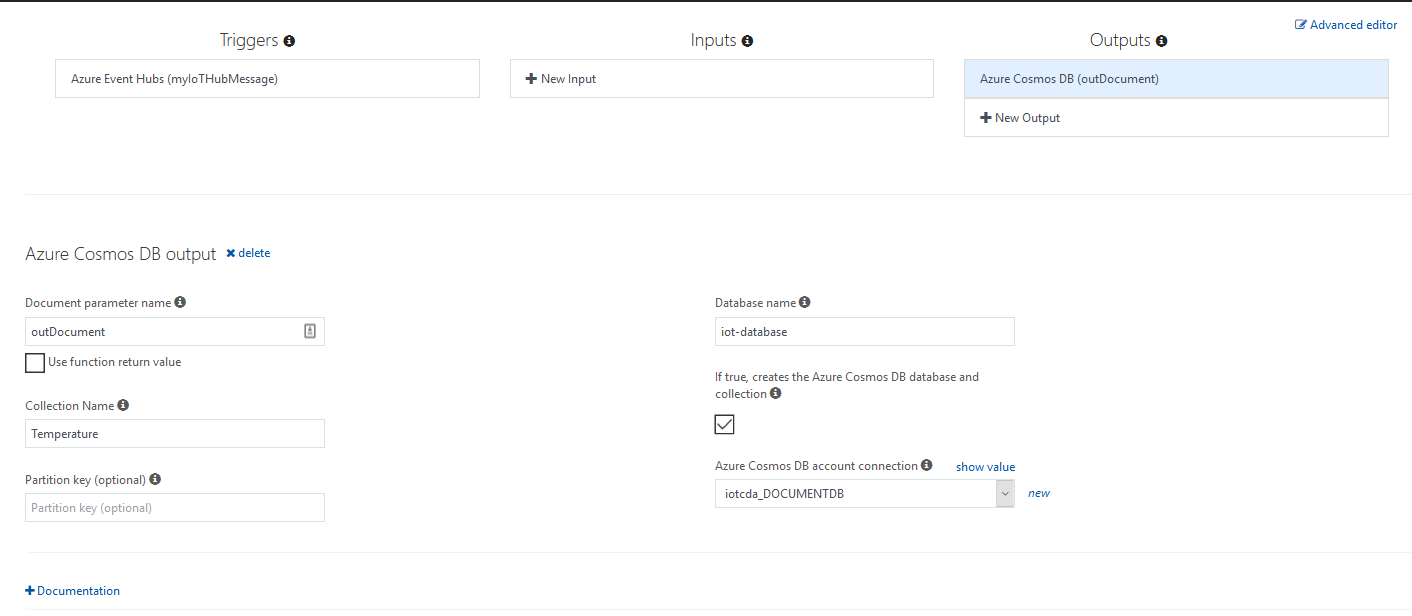
In this section, I created a new connection to my Cosmos DB account where save our messages. As you can see, if you check the right checkbox, you don’t need to create any collection or databases manually.
On Automating
As you can see, I’m being all fancy and creating everything through a Portal UI. Everything I’ve done can be replicated with an ARM Template that will allow you to provision your different resources and bind your connection strings together.
If you are interested in seeing a way to deploy this through the command line, please let me know in the comments.
Results
After everything has been hooked up together, I sent a few manual event on my IoT Hub and looked into my Cosmos DB account.
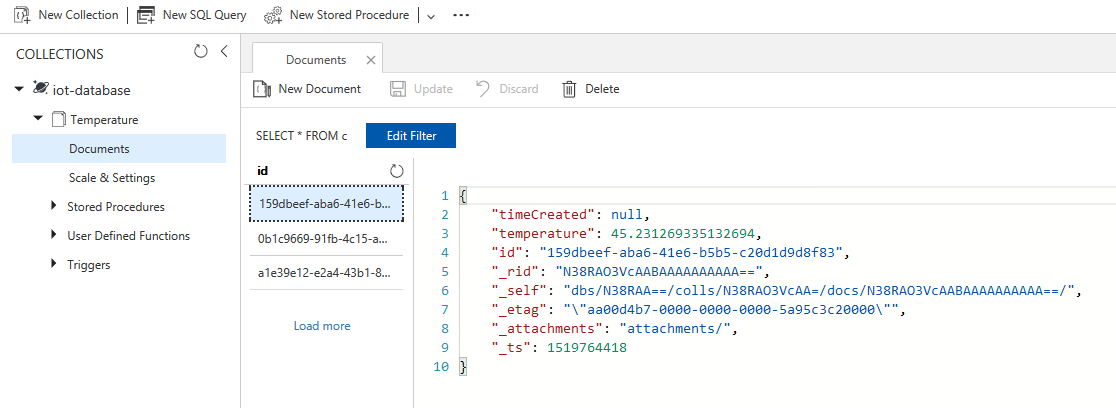
Amazing!
Want more?
So what we just saw was a very cheap and scalable way to receive a ton of events from thousands of devices and store them in Cosmos DB. This will allow us to either create reports in Power BI, consume them in Machine Learning algorithms or stream them through SignalR to your administrative dashboard.
What would you be interested next? Let me know in the comment section.