After my previous post, we managed to find out what flavor of App Service to use (resumed at the top of the post by a famous tldr).
But other question I receive is often? Should I use a WebApp (read: AppService) or a Cloud Service? What’s the difference? Just like anything slightly complicated, the answer is “it depends”. I know! It’s a classic obscure response. The reason is that there is no silver bullet. If there is no silver bullet, it means we have to look at your current scenario and try to compare it with use cases that fits the solutions.
So let’s try to dive-in a bit on use cases that warrant a WebApp and on those that would suit a Cloud Service better.
What is an AppService?
An AppService allows you to host a web application (API or UI) very easily within seconds.
If you are looking to iterate quickly, this is your option. Deployments take usually seconds from your machine. AppServices also allow you to quickly scale up (up to 10 instances) and out either by responding to metrics (CPU/Memory/Queue length) or manually through the portal. You can share resources by grouping your web applications within App Service Plans. Applications are hosted on the *.azurewebsites.net domain. Each additional instance that are created to answer to the demand contains a copy of your content and configuration of your application. No need to replicate anything. As we don’t always deploy in production, it’s possible to create a staging environment where you can release a preview build and test it out in the real production environment for vetting.
AppServices is PaaS so no need to handle Windows Updates or any kind of patching. If you don’t want to deploy with Visual Studio, you can do deployment with GitHub, Dropbox , FTP or Web Deploy.
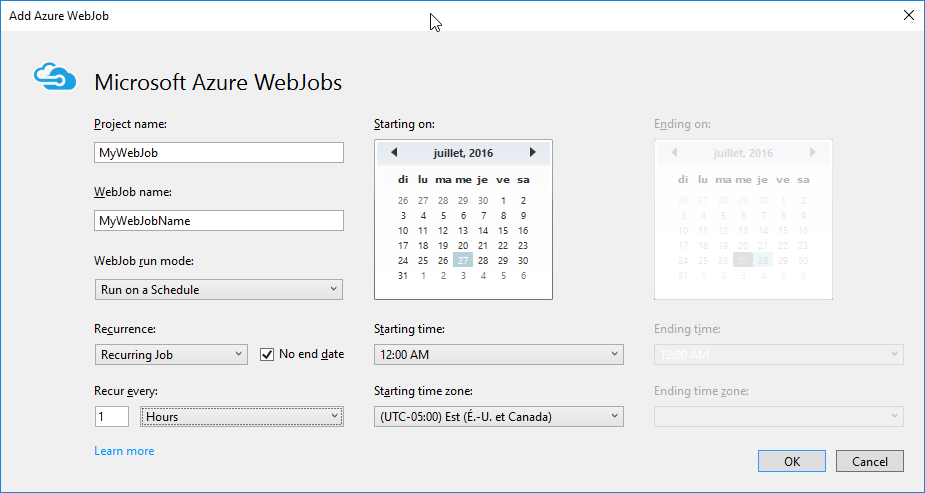
All applications requires to run some jobs on schedule or to answer to events from a queue. In those cases, WebJobs can be easily deployed and share the resources of the current web application.
Supports applications written in .NET, Node, PHP, Python, Java.
What is a Cloud Service?
A Cloud Service allows you to host anything on a compute resource running Windows that can scale to hundreds of machines.
If you are looking for an application that can take almost any type of traffic/load, this is your option. Deployment are longer. They will usually take a few minutes to deploy new releases. Just like AppServices, it does support multiple staging environment and allow you to scale up to tremendous amounts (up to 1000 instances) by responding to metrics (CPU/Memory/others) or just manually through the portal.
You can host 25 roles (Web/Worker) per service and independently scale them each to 1000 instances. If you want a rolling deployment instead of “all at once”, Cloud Service is where it shines. It can deploy to each instance gradually instead of all instances at once unlike AppServices.
Need to Remote Desktop into the Cloud Service to see what is going on? Totally possible.
Cloud Service is a PaaS service and will receive all OS patches automatically and, if configured properly, without any down time.
However, it does not do GitHub deployment, it will not automatically integrate APIs with Logic Apps or Biztalk Services.
When do I want to use an AppService?
When you want to…
- Enjoy fast deployments from many sources
- Creating web application that are not too resource hungry
- Creating APIs that need to integrate with Logic Apps
- Create a minimum viable product
- You are using .NET, Node, Python or Java
- Run maintenance jobs
- Limit your expenses and save money
Common scenarios are…
- Hosting a blog
- Hosting an e-commerce
- Hosting a public company website
- Creating any application for a client (Note: I always start with AppServices)
- Run small jobs on a specific schedule or upon requests (with or without web hooks)
- Polling data feeds
- Cleaning up SQL databases
- Send notifications
When do I want to use a Cloud Service?
When you want to…
- Create powerful applications that can scale to massive numbers
- Handle massive amount of traffic
- Independently scale background processes from the front-end
- Run non-trivial background task
- Remote desktop onto the machine
- High amount of control over the configuration
- Ensure a proper separation between your instances/roles running your application (including security reasons)
Common scenarios are…
- Running specific tasks that require Windows APIs that are not available in AppServices (GDI+, COM, etc.)
- Hosting Fortune 500 e-Commerce
- Running parallelizable CPU/memory intensive tasks
- Running long running tasks
- Running code with elevated privilege
- Installing custom software on the VM (framework, compilers, others)
- Was running on AppServices but exceeded the capabilities of the service
- Moving some legacy applications from a home data center to the cloud
Conclusion
In the end, it’s all about what you need.
Most of the time, clients don’t need more than AppServices to start deploying applications and see what Azure can bring to the table. When the scenario requires it, it’s our job to orient the technological choice toward the right solution.
While AppServices may suffice for 80% of a customer’s need, the other 20% will have you dig your hands into Cloud Services or even Azure Batches (more on that later!).
I hope that I managed to help you make a decision today. If you have questions, do not hesitate to comment!

 .
.